Stream 생태계 정리
이 글에서는 Node.js Stream API 생태계를 정리한다.
TODO:
- 스트림을 제대로 써봐야 제대로 이해할 수 있을 것 같다.
- 스트림 생태계가 좀 엉망인데 직접 사용해보고 정리하는 기회가 필요할 것 같다.
- 이 글도 예제를 제대로 추가해 영양가 있는 글로 만들어야 한다.
이 글에서는 Node.js Stream API 생태계를 정리한다.
TODO:
이 글은 Stream에서의 Pipe, Fork, Merge, Mux/Demux 패턴에 대해 소개하고 Mux/Demux는 예를 제공한다.
참고 자료:
여기서 말하는 Pipe 패턴이란 스트림의 조합으로 이루어진 하나의 파이프라인을 모듈화하고 재사용하는 방법을 말한다.
Pipe 패턴 구현 시 주의할 점
Combined-Stream 패키지를 이용한다. (사용량은 압도적이나 Stream v1 - Flowing 모드만 지원한다.)
(Pumpify가 더 좋은 것 같은데 사용법을 잘 모르겠다.)
서로 다른 대상에 동일한 데이터를 보내는 경우, 즉 하나의 Readable에 2개 이상의 스트림을 연결하는 패턴이다.
Fork 패턴 구현 시 주의할 점
.pipe 사용 시 {end: false} 옵션이 필수가 된다. 한 쪽의 작업이 끝나는 경우 다른 쪽도 닫히기 때문일련의 Readable을 하나의 스트림으로 연결하는 패턴이다. .pipe({end: false})로 연결해야 한다. Auto End 옵션은 하나의 Redable만 종료되더라도 연결된 스트림까지 종료시키기 때문이다.
Merge-Stream 패키지를 사용한다.
(직접 구현한다.) 여러 스트림에서 들어오는 데이터를 한 스트림(이 예에서는 net 패키지의 도움을 받아 TCP Socket을 사용한다.)으로 내보내고, 같은 방식으로 데이터를 받아들인 후 여러 스트림으로 다시 분류하는 멀티플렉싱/디멀티플렉싱을 스트림 수준에서 구현한다.
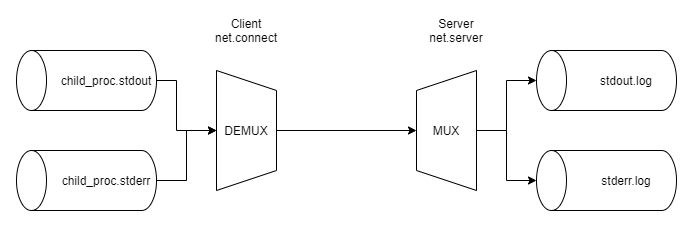
긴 설명은 하지 않고, 코드에 주석을 달아 놓았으니 흐름을 따라가면 쉽게 이해할 수 있을 것이다.
generateData.js
표준 출력, 오류 스트림에서 데이터를 생성하기 위한 코드이다. Client에서 실행하게 된다.
1 | console.log("out1"); |
Client.js
generateData로 생성된 데이터가 표준 출력, 오류 스트림으로 들어오게 되고, 아래 코드에서 헤더로 포장한 후 Socket으로 Server에 전송한다. (참고로 Client 코드가 이 case에서 가장 어렵다. 이 코드만 이해하면 다 했다고 볼 수 있다.)
1 | const child_process = require("child_process"); |
Server.js
클라이언트로부터 데이터를 파싱한 후 각 스트림에 대응되는 파일에 내용을 쓴다. 헤더 격인 앞 1바이트를 읽어 채널을 구분한다.
1 | const net = require("net"); |
TODO:
이 글은 Stream을 사용할 때에 순차 실행, 병렬 실행, 제한된 병렬 실행에 대해 다룬다. 또한 독자가 Node.js Stream에 대한 기초 지식이 있음을 전제로 작성되었음을 밝힌다.
참고 자료:
스트림은 당연하게도 비동기로 작동한다. 여러 개의 Redable Stream이 있고 하나의 Writable Stream이 있을 때, 각 작업들을 순차적으로 수행하는 방법이 있을까? 가능하다. 여러 개의 Readable 을 각각 Writable로 연결하고, Redable에 순서를 지정하면 된다. 아래 코드에 대한 설명은 주석으로 나타나 있으니 주석을 따라가기 바란다.
1 | const fromArray = require('from2-array'); |
http://thiswillbedownforsure.com is down
https://www.naver.com is up
https://www.google.com is up
위와 같이 특정 사이트 목록들에 대해 health check를 하고 그 결과를 파일로 출력하는 프로그램을 만든다고 하자. 굳이 Stream으로 만들 필요는 없겠지만 그렇게 해본다면 다음과 같은 코드를 생각해볼 수 있다.
일단 Transform 기반의 스트림을 하나 정의한다. 이 스트림은 request의 콜백으로 스트림의 기능을 빌려주는 형태로 작동한다.
1 | // Transform 스트림을 하나 정의한다. |
위에서 정의한 스트림을 사용해 구현한다.
1 | /* |
비동기 요청 여러 개를 처리하는 일은 Node.js에선 매우 간단하다. Run to Completion이기 때문에 변수 하나로 비동기 작업의 개수를 정확히 세고 이 값에 기반해 의사 결정을 할 수 있다.
따라서 this.running의 개수가 동시 실행 제한 개수에 도달한 경우 처리하지 않으면 된다. 좀 더 정확하게는, _transform 함수에서 해당 chunk의 처리가 완료됐음을 알리는 콜백을 호출하지 않고 보류하면 된다.
이 경우 해당 chunk를 처리한 결과는 다음 스트림으로 넘어가지 않으며 현재 chunk가 처리되지 않았기 때문에 추가적인 chunk가 스트림으로 전달되지도 않는다(스트림 내부 버퍼에 쌓인다).
만약 ReadableStream이 chunk를 생성하고 내보내는 속도가 우리의 스트림의 처리 속도보다 빠르다면 처리되지 않는 chunk는 Transform의 버퍼에 쌓이며 이내 백 프레셔가 발동되고 알아서 처리될 것이다. - pipe로 연결하면 Node.js에서 자동으로 처리한다. 백 프래셔에 대해선 5장 Stream API (2/3) - Node.js의 4가지 스트림 소개와 사용법을 참고하라.
따라서 추가적으로 신경써야 하는 부분은 출력을 할 지 여부를 결정하는 것이다.
1 | constructor(concurrency, userTransform) { |
참고 자료 (이번 글만 특별히 도움이 됐는지와는 별개로 읽은 몇 개의 글을 링크한다.):
What’s the proper way to handle back-pressure in a node.js Transform stream?
Awesome Nodejs#Streams (Github Repo)
TODO:
이 글은 Node.js 디자인 패턴 CH 05 스트림 코딩의 일부를 참고해서 작성하였으며, Node.js에서 코어 모듈로 제공하는 Stream 4종류를 다룬다. Node.js에서의 스트림 자체에 대해서는 5장 Stream API (1/3) - 스트림 개요 및 Readable Stream를 참고하라.
Node.js에서는 4가지의 추상 스트림 클래스를 제공하여 쉽게 스트림을 구현할 수 있게 한다. 이 클래스들은 core 모듈에서 제공하므로 추가 의존성이 필요하지 않다.
| Name | 목적 | dataSource 가능 |
|---|---|---|
| stream.Readable | 외부 데이터 읽기 (dataSource에서 꺼내는 형태) | True |
| stream.Writable | 내부 데이터 외부로 전송하기 (dataSource로 써주는 형태) | False |
| stream.Duplex | Readable + Writable 스트림. | True |
| stream.Transform | 외부 데이터 읽기 => 데이터 변조하기 => 외부로 전송하기 | True |
Node.js에는 두 가지의 Stream API가 있다.
| API Version | Name | Event Name | Description |
|---|---|---|---|
| Stream v1 | Flowing Mode | on('data') |
무조건 해당 데이터를 처리해야 함. 버퍼 크기 등의 문제로 처리하지 못 하는 경우 해당 데이터를 되살릴 방법이 없음. |
| Stream v2 | Non-Flowing Mode | on('readable') |
곧바로 데이터를 처리하지 않아도 됨. 백 프래셔를 지원함. |
Back Pressure: Event 송신자의 처리량이 Event를 수신하는 측의 처리량을 넘기는 경우 송신자의 전송 속도를 줄여야 하는 경우가 생기는 데 이를 해결하는 메커니즘을 Back Pressure라고 한다.
송신자-수신자 처리량 차이 발생 오류 백프래셔 필요 송신자 전송량 < 수신자 처리량 없음 False 송신자 전송량 > 수신자 처리량 처리하지 못하는 데이터에 대한 정의되지 않은 동작 등 손실 발생 가능 True Stream v2의 백 프래셔:
Node.js의 버퍼가 알아서 버퍼링을 해주며, 버퍼 한계치를 넘으면 OS에서 패킷을 drop시켜 sender 입장에서 전송 속도를 늦추게 함. 이 기능을 자동으로 지원. (v1도 가능하다고 함. 다만 더 어렵다고 함.)출처: What are the differences between readable and data event of process.stdin stream?
추가 참고:
Readable 스트림은 데이터를 읽어들이는 게 목적이다.
stream.read() 함수를 사용하면 chunk를 반환한다.
1 | const RandomStream = require("./randomStream"); |
Readable Stream은 _read 함수를 구현하면 된다.
1 | const stream = require('stream'); // 코어 모듈 (stream) |
Writable 스트림은 데이터를 생성하는 게 목적이다. (ex) HTTP response 생성
stream.write 함수를 사용하면 스트림에 내용을 쓸 수 있다.
1 | // res가 Writable Stream 이다 :) |
(윗 코드와는 상관 없음.) Writable Stream은 _write 함수를 구현하면 된다.
1 | class ToFileStream extends stream.Writable { |
백 프래셔란 Read보다 Write가 빠를 때 병목이 생기는 것을 방지하는 메커니즘이다.
1 | require("http") |
Duplex Stream은 Readable + Writable 그 이상 그 이하도 아니며 따라서 설명을 생략한다.
Transform 스트림은 읽어들인 데이터를 변조해 내보내는 스트림이다. 스트림이니만큼 chunk 단위로 데이터가 오므로 변환에 유의해야 한다.
1 | const ReplaceStream = require("./replaceStream"); |
스트림 상에서 문자열 일부를 치환하는 코드이다. (어렵다.)
1 | class ReplaceStream extends stream.Transform { |
TODO: (전부 다 책에서 나온 내용)
스트림 간의 Pipelining(조합) 소개
스트림 기반 비동기 제어 소개 (순차/비순차/제한된 비순차)
스트림 fork, merge
스트림 멀티플렉싱, 디멀티플렉싱
소스 코드 출처: Node.js 디자인 패턴
스트림 파트는 내가 스트림에 대한 경험도 거의 없고 책에서 설명하는 내용이 어려워서 내 생각을 넣어 포스팅하기가 매우 어려웠다. 내용을 간략히 정리하는 선에서 마쳐야 할 것 같아 아쉽다.
이 글은 7장 의존성 주입 (1/2)에서 설명한 DI 컨테이너의 간단한 구현체를 제시한다. Javascript이기 때문에 타입 정보를 얻을 수 없어 String으로 의존성을 판단하는 부분을 참고하기 바란다.
이 글의 코드는 출처에서 배포된 코드를 가져왔음을 밝힌다.
아쉽게도 패키지 전체를 미리 스캔하여 자동으로 의존 관계를 파악하고 의존성 주입을 수행하지는 않는다. 기능은 크게 get, factory, register가 있다. 자세한 설명은 주석을 참고하라.
1 | ; |
DI 컨테이너에 각 객체를 등록하는 과정을 이 파일을 진입점 삼아 수행하였다. 좀 더 좋은 DI 컨테이너라면 Reflection 등을 이용해 자동으로 mark된 객체를 등록하고 의존성 주입을 진행할 것이다.
1 | ; |
의존성 주입이 적용되는 객체 1이다. 주석 참고.
1 | ; |
의존성 주입이 적용되는 객체 2이다. 주석 참고.
1 | ; |
TODO:
Node.js 스트림 이어서 포스팅하기
이 글은 Node.js/Javascript 환경에서의 한 패키지(App) 내의 모듈 간의 의존성을 관리하는 방법에 대해 다룬다. 명시하지 않은 경우 Javascript 환경임을 미리 밝힌다.
Typescript는 지금까지 많이 활용돼왔고 생태계가 성숙한 상태이므로, OOP 방식으로 문제 해결을 하려는 경우 Typescript가 적정 기술이라고 생각한다.
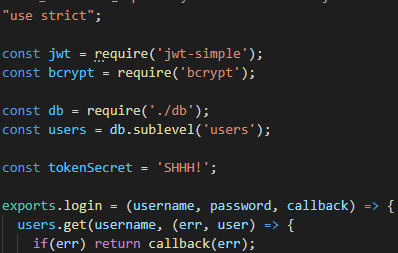
백엔드와 같이 쉽고 빠르게 규모가 커지고 기능 변경이 잦은 코드 베이스인 경우 설계가 중요한 경우가 많을 것이다. 설계는 의존성 관리가 기본이며 Node.js 백엔드 또한 그 예외는 아닐 것인데 말이다.
Q. 왜 Node.js에서는 하드 코딩된 의존 관계를 구축하는 코드를 찾기가 매우 쉬울까?
A. 가설: 인터페이스와 상관 없이 임의의 객체를 집어 넣어 테스트를 할 수 있기 때문에 굳이 Interface가 필요하지 않다. 동적 타입 언어이니까.
만약 Java 였다면 Interface를 아예 사용하지 않는 것은 설계에 큰 문제가 있음을 시사하는 것이겠지만 Javascript는 동적 타입 언어이다. 기능을 실행하는 객체의 타입이 중요하지 않은 언어이다. 인터페이스가 없는 만큼 규칙도 없지만 그만큼 유연해진 셈이다.
다만 동적 타입을 활용해 테스트가 가능하다고 해도 자연스럽게 생기는 강한 결합이 사라지는 것은 아니다. 구현체에 직접 의존하면 강한 결합이 발생한다. 의존하는 객체의 구현 상세에 대한 아무런 격리 장치가 없으며 구현체에서 변경이 생겼을 때 해당 의존성을 사용하는 모든 객체에 그 여파가 전달되므로 다시 검증(테스트), 빌드해야만 한다.
OOP 에서는 인터페이스를 미리 정의하고 해당 인터페이스를 최대한 변경하지 않음(Open Close Principle)을 통해 문제를 해결한다. 인터페이스에 의존함을 통해 구현 상세와 사용 객체를 진정으로 격리시킬 수 있으며 이는 의존성 관리에 매우 큰 역할을 한다.
의존성에 의한 강한 결합을 막는 수단은 현재로썬 서비스 로케이터 패턴과 의존성 주입이 있다.
이제부터 이 글은 Javascript/Node.js 에서의 의존성 주입에 대해 다룬다.
서비스 로케이터 패턴이란 “의존성이 있는 각 객체가 서비스 로케이터 객체만을 직접 의존하고, 각 객체는 서비스 로케이터에 의존성을 명시해 구현체를 받아오는 것“을 말한다. (서비스 로케이터 패턴에 대해 더 자세히 알고 싶다면 이 글을 참고하라.)
아래 예는 AuthController가 AuthService에 의존하는 코드이다.
1 | // AuthController.js - AuthService에 의존한다. |
의존성의 구현체에 의존하지 않게 해준다. 이는 의존성 주입과 동일한 장점이며 아주 좋은 장점이다.
객체의 구현 코드를 보지 않으면 곧바로 의존 관게를 파악할 수 없다. 생성자 등으로 명시하지 않기 때문에 - 생성자의 파라미터로 명시한다면 필수값이라는 문서화의 역할을 수행하게 되는데 비해 - 모든 객체에 대해 문서화가 필요하다.
의존 관계를 가장 잘 다루는 방법은 아마도 DI일 것이다. Javascript 진영에선 Angular가 최초로 의존성 주입을 도입한 것으로 안다(Typescript도 없던 시절이었는데!).
의존성 주입이란 “모듈의 의존성을 외부 개체에 의해 입력으로 전달 받는 것“을 말한다. 의존성 주입의 개념 자체는 매우 간단하다. DI를 지원하기 위한 컨테이너와 지원 방식을 구현하는 게 어려울 뿐이다.
(ex) AuthController가 AuthService에 의존하는 경우의 예시를 확인하자.
Before DI: 구현체를 직접 가져오는 모듈
1 | // 직접 가져온다. |
After DI: 의존성을 받아오는 모듈
1 | // authService를 전달 받아서 사용한다. authService의 출처와 구현체에 대해 아는 것은 더 이상 이 객체의 책임이 아니다. 그냥 사용만 하면 된다. |
Service Locator / DI Container의 간략한 구현도 포함하려고 했으나 2편에서 다루도록 하겠다.
약간의 짬을 내어 찾아보니 크게 4개의 오픈소스 컨테이너들이 있었다: InversifyJs, tsyringe, typedi, awilix (점유율 순).
tsyringe는 Microsoft에서 만들었다. 재밌는 점은 MS에서 inversifyjs를 사용한다고 나와있는 것이다. NestJs는 DI를 Core에 내장하여 차트에 포함시켰다.
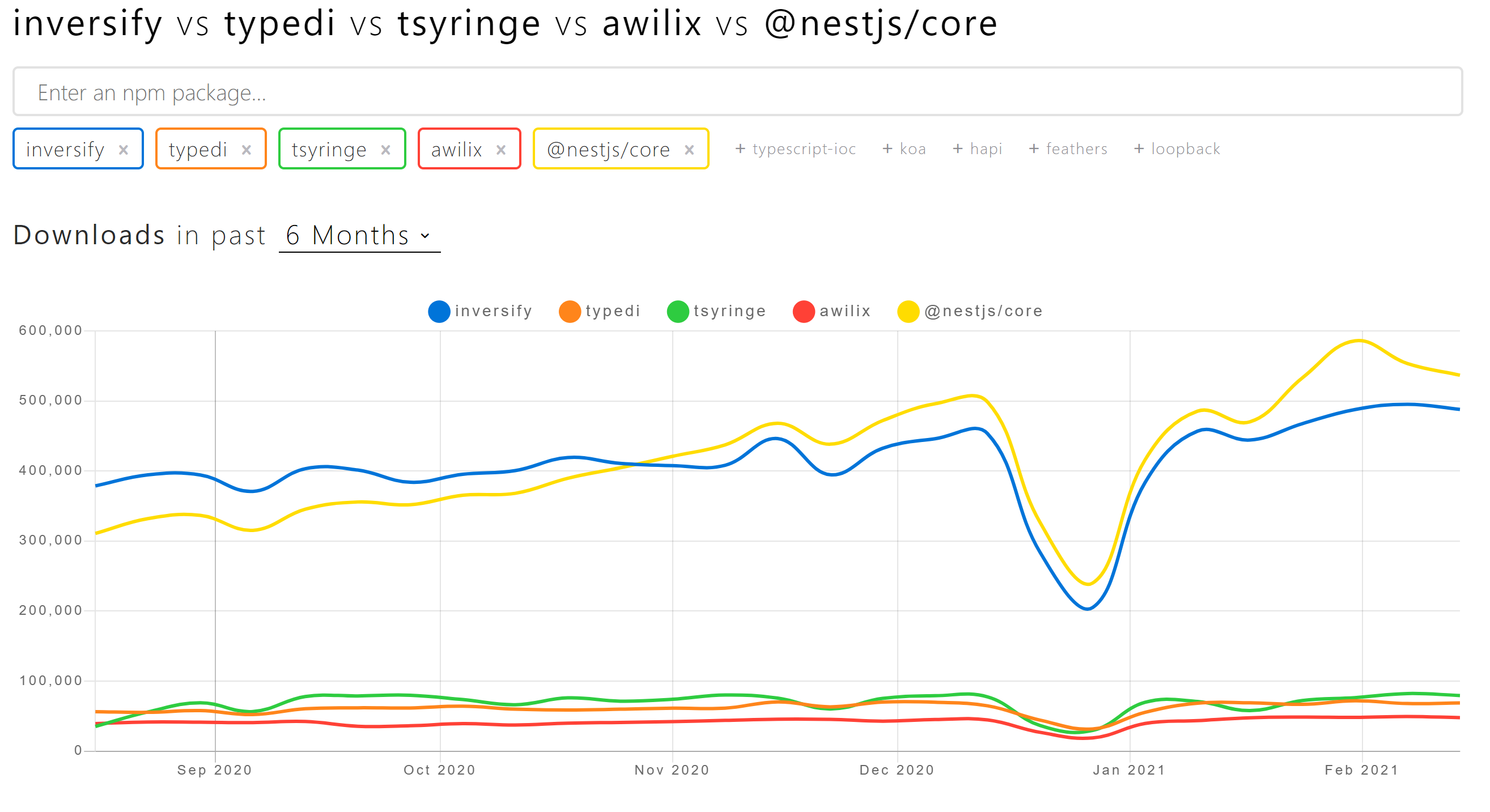
각 라이브러리의 자세한 비교는 기회가 된다면 추후 진행하려 한다.
require과 서비스 로케이터 패턴의 관계에 대해 이해해야겠다.CS에서 가장 자신있던 객체지향을 이렇게 모르게 됐다는 게 새삼 충격적이다 :(
이 글은 Node.js 디자인 패턴 CH 05 스트림 코딩의 일부를 참고해서 작성하였다. 이번 글은 Stream API에 대해 깊이 다루기보다 스트림 자체에 대해 다룬다.
스트림은 파일을 버퍼 단위로 옮겨서 전부 옮길 때까지 기다린 후 처리하기보다 매 버퍼 단위로 전송하는 방식이다.
스트림은 본질적으로 비동기 패러다임으로, 기다린 후 처리하는 Sync 방식에 대비된다. 물론 fs.readFile 역시 Node.js 런타임에서 I/O를 처리해주니 스레드가 Block 되진 않겠지만, 애초에 I/O 수준에서도 기다릴 일이 없게 하는 것이 처리량에서 우위이지 않을까?
(처리량에서 정말 우위일지는 잘 모르겠다. 스트리밍 오버헤드에 대해 공부해본 적이 없기 때문.)
스트림은 메모리에 파일의 전체 내용을 올리지 않고 버퍼의 크기만큼만 메모리를 할당하기 때문에 공간 효율적이다. 더 좋은 점은 파일의 크기에 상관 없이 일정한 양의 메모리를 점유한다는 점이다.
이것과 별개로 V8 엔진은 32bit 기준 ~1GB, 64bit 기준 ~1.7GB 정도의 메모리만 사용하도록 설정돼있어(더 높이려면 빌드해야 함.) 파일이 큰 경우 전체 파일을 한 번에 메모리에 올릴 수 없음.
공간 비효율적인 파일 압축 코드 (ex: example.tar -> example.tar.gz)
1 | const fs = require('fs'); |
공간 효율적인 파일 압축 코드 (Stream API)
1 | const fs = require('fs'); |
참고로 gzip이 어떻게 스트림에 대해 동작하는지 궁금하다면 아래 글들을 참고해보면 좋을 것 같다.
How is it possible to GZIP a stream before the entire contents are known? | StackOverFlow
How does gzip compression rate change when streaming data? | StackOverFlow
Stream은 TTFB(Time to First Byte)에 강점이 있는데, TTFB는 파일의 크기에 비례하여 빠를 수 밖에 없다. 파일의 크기가 클 수록 읽는 데 대기시간이 필요하지만 Stream은 곧바로 응답을 보내기 시작하기 때문이다.
웹에서 TTFB는 매우 중요하다.
자세한 건 Next.js의 재밌는 이슈(Stream rendering to reduce TTFB and CPU load) 참고.
다음의 사이클을 단 1회 거치게 된다: read > compress > send > receive > decompress > write
위의 사이클을 매 chunk마다 거치게 되므로 파이프라이닝과 같은 형태로 병렬 처리가 가능하다. 물론 chunk의 크기마다 다르겠지만 각 단계를 거치는 만큼 오버헤드가 있을 것이다. (HTTP header 등. 이 부분에 대해선 잘 알지 못한다.)
Node.js 동시성을 활용하는 것이므로 순서를 맞춰줘야 하는데 Stream API가 알아서 처리한다고 한다.
아래는 파일을 전송하는 스트림 예제 코드이다.
client: 파일을 받아 디스크에 쓰는 역할
1 | const http = require('http'); |
server: 파일을 읽고 전송하는 역할
1 | const fs = require('fs'); |
스트림은 Composition으로 문제 해결을 한다. Express Middleware와 같이 마음껏 파이프라인을 만들어낼 수 있다.
스트림을 기반으로 비동기 이벤트를 처리하는 패러다임을 Reactive라고 하고 이를 위한 RxJS가 있다.
(ex) 암호화 기능 추가
1 | // 복호화 |
Node.js가 지원하는 스트림은 EventEmitter 객체를 상속하며 binary, 문자열 뿐만 아니라 거의 모든 Javascript의 값을 읽을 수 있다. 이러한 스트림에는 크게 네 종류가 있는데 이번 글에서는 (글이 길어지는 관계로) Readable만 다룬다.
Readable 스트림은 외부에서 읽기 위한 스트림으로, 자신이 가진 값을 chunk로 써서 내보내는 역할이다.
사용 예:
readable이벤트에 listener를 등록하고 이벤트 발생 시 버퍼에 있는 내용을 모두 읽기
API로는 아래의 함수가 있다.
readable.read([size]) // read는 동기 함수이다.
(ex) 표준 입력(stdin) 받아서 표준 출력(console.log, stdout.write)하기
1 | process.stdin |
Stream v1, v2에 따라 non-flowing mode, flowing mode 로 나뉘는데 어차피 v1은 사용되지 않으므로 설명을 생략한다.
지금까지는 fs, http의 스트림을 그대로 사용했지만 직접 ReadableStream을 만들어 활용할 수도 있다.
stream.Readable을 상속해 abstract function인 _read([size])(public 인터페이스인 read와 헷갈리면 안 된다)를 구현하면 ReadableStream 객체를 하나 만들 수 있다.
구현을 위해 push(data[, encoding]) 함수를 호출해 내부 버퍼에 값을 쓸 수 있다.
1 | const stream = require('stream'); |
나머지 스트림 종류 다루기
백 프래셔
스트림 기반 비동기 제어
Pipe Composition
멀티 플렉싱, 디멀티 플렉싱
Node.js 환경에서 CPS 패턴을 사용할 때 시도할 만한 Tip들을 정리했다.
본인은 Promise 세대여서 Callback Hell을 제대로 경험해 본 적이 없고, 웬만한 개발 환경이라면 Callback Hell을 겪기 어려울 것으로 예상돼 짧게 요약했다.
들여 쓰기 때문에 가독성이 매우 떨어지게 되고, 변수 이름도 중첩되는 문제가 있다. 만약 Blocking API를 사용해 동일한 내용을 구현했다면 잘 못 이해할 가능성은 거의 없을 것이다.
Pattern:
자주 하는 실수:
Callback을 호출한 뒤에도 함수는 계속 실행됨을 잊는다.
1 | if (err) callback(err); |
return callback(err) 혹은 return을 callback 호출 이후 수행하여 함수 실행을 종료한다.Callback Hell을 겪지 않고 비동기 API를 순차적으로 실행하는 방법:
1 | const length = N; |
이 방식의 한계:
Javascript는 단일 스레드로 실행된다.
리소스 동기화는 필요 없지만, 비동기 API 타이밍 문제는 아직 남아있다.
Javascript 역시 호출 시점과 I/O 수행 시점 차이로 중복 작업 등의 예기치 않은 동작을 할 수 있다.
상호 배제로 해결 가능하다.
1 | // 실행 중인 job을 등록한다. 공유 리소스 동기화는 필요 없다. |
한 번에 너무 많은 파일을 열려고 하는 등의 경우 리소스 부족으로 뻗어버릴 수 있다. 동시에 실행하는 작업의 수를 제한해 이를 상황을 방지하는 아이디어를 소개한다.
알고리즘:
동시 실행 제한 개수 - 현재 실행 개수 만큼의 작업을 실행1 | const tasks = [ |
큐로 구현하는 방법:
1 | // Queue로 구현하는 방식 |
복잡한 비동기 제어 흐름을 선언적인 방식으로 처리할 수 있게 헬퍼 함수들을 제공하는 라이브러리이다.
등을 헬퍼 함수를 통해 쉽게 구현 가능하다. CPS 패턴은 주로 사용할 것 같진 않아 따로 정리하진 않았다.
TODO:
이 글은 Node.js에서 자주 사용되는 Observer Pattern에 대해 소개한다. 리액터 패턴, CPS 패턴에 대한 지식을 전제로 작성했으니 참고바란다.
Node.js에서 이벤트는 핵심 중 하나라고 한다.
Node.js 코어 모듈과 오픈 소스를 사용하는데도 필수적인 조건이라고 한다.
Observer Pattern은 Subject와 Listener 라는 역할로 한 쪽은 등록을, 한 쪽은 통지를 하는 관계이다.
Subject는 이벤트를 발생시키는 주체로, 스스로 무슨 행위를 할 때, Listener에게 통지를 해야 한다.
Listener는 특정 Subject 객체에 본인의 참조를 등록한다. subject.addListener(this)와 같이 수행한다.
foreach (listener : listeners) listener.notify(); 와 같이 Listener에게 이벤트 발생을 알린다.
옵서버 패턴 | Wiki 백과 참고.
Observer Pattern이 Callback 보다 나은 점이 뭘까?
| 기능 | Observer Pattern | Continuous Passing Style |
|---|---|---|
| 다중 리스너 지원 | Yes | No |
| 핸들러 사용 횟수 | 여러 번(or 주기적으로) 발생하는 경우 | 한 번 발생하는 경우 |
| 핸들러 함수 제약 | 없음. onError, onSuccess 로 관심사 분리하므로. |
한 함수 (err, data)=> { /* ... */ }로 두 상태 모두 처리 |
| 핸들러 등록 시점 | 아무 때나 | 함수 실행 시점에 매개변수로 전달 |
Node.js는 Event Emitter라는 미리 구현된 객체를 코어 모듈(events)로 포함하고 있다. 이 객체는 emit, on, once, removeListener 로 구성된 총 4개의 메소드를 갖고 있다. 아래는 각 메소드의 사용 예시이다.
CodeSandBox가 Node.js를 Beta로 지원하고 있으므로 출력이 정상적이지 않을 수 있습니다. 왼쪽의 탭을 드래그해 코드를 확인해주세요.
아래는 File을 읽는 예제이다.
Event Emitter에서도 비동기 이벤트의 경우, CPS와 마찬가지로 예외가 발생하는 경우 기존 스택을 잃기 때문에 (리액터 패턴 참고) try-catch로 무조건 예외를 처리하여야 한다. 이후 error 이벤트를 발생시켜 리스너들에게 전달함이 일반적이다.
아래와 같이 EventEmitter를 상속하여 인스턴스에 대해 .on을 붙이는 등의 작업을 할 수도 있다. 책에서는 일반적인 패턴이라고 하지만, emit 메소드까지 의도치 않게 Public API가 되기 때문에 추천하는 방식은 아니다. 위임으로 on, once, removeListener를 따로 API로 내보내는 게 맞다고 생각한다.
1 | class FindPattern extends EventEmitter { |
이벤트를 동기적으로 발생시키려면, 리스너 등록을 이벤트 발생 이전 시점에 완료하여야 한다.
이벤트를 비동기적으로 발생시키는 경우, 리스너를 동기적으로만 등록한다면 시점이 자유롭다. (리액터 패턴 참고.)
이 글은 Node.js의 모듈 시스템에 대해 소개한다.
모듈 시스템은 프로그램의 구성 요소들 간의 역할을 분리하고, 의존 관계와 구현 상세를 격리하는데 필수적이다. 모듈 시스템의 문법으로 보면, 소스 파일간의 import, export를 하는 것인데, 개념 상 Java의 접근 제한자 - private, protected, public - 도 모듈의 역할 중 일부를 수행 한다고 할 수 있다.
Javascript 모듈 시스템으로는 대표적으로 ESM, CommonJs 라는 두 개의 기술이 있는데, 현재의 Node.js는 ESM, CommonJs를 모두 지원한다.
| 종류 | ESM | CommonJS |
|---|---|---|
| 제정 시기 | ES6에 제정됨 | ESM 이전의 대표적인 비표준 |
| 문법(Node 기준) | import / export |
require / module.export |
| Node.js 지원 여부 | Yes | Yes |
| Browser 지원 여부 | 최신 브라우저에서 지원 | CommonJs.js 로딩 필요 |
자세한 역사와 기타 모듈 시스템의 종류는 JavaScript 표준을 위한 움직임: CommonJS와 AMD | Naver D2를 참고.
Javascript에는 접근 제한자가 없다. 접근을 원천적으로 제한하는 방법 중, 공개할 부분만 객체로 담아 내보내는 패턴이 있다. Private 변수는 클로저를 통해 접근할 수 있으므로, 꽤 괜찮은 방법이다.
Revealing Module 패턴을 구현하는 방법은 대표적으로 IIFE(즉시 실행 함수 표현식)가 있다. IIFE는 익명 함수를 ()로 감싼 후 즉시 실행하는 함수 호출 방식이다.
1 | const module = (() => { |
CommonJs는 const moduleA = require('./moduleA');와 같이 모듈을 로딩하는 문법을 제공한다. require는 동기로 작동하고, 한 번 로딩한 모듈은 캐시된다. 내보낼 때에는 각 모듈별로 제공되는 exports 객체에 필드를 할당하는 방식으로 진행한다.
모듈은 캐싱되므로 항상 동일한 객체를 반환한다.
아래는 require의 수도 코드이다.
1 | const require = (modulePath) => { |
어느 범위까지 같은 인스턴스가 반환될까?
같은 패키지로 빌드된다면 하나의 인스턴스를 공유할 것이다.
package.json별로 독립적으로 dependency를 관리하기 때문에, 각 패키지간에 제 3의 모듈의 객체를 주고 받는 경우, 해당 객체는 버전 불일치가 있을 수 있다.
A Simple Explanation | Medium (EN)
비동기로 객체를 초기화할 순 없다. require 함수가 동기로 작동하기 때문인데, 아무래도 initialize와 같은 메소드를 호출하는 형태로 비동기 API를 만들어서 활용하는 수 밖에 없을 듯하다.
관련 스택 오버 플로우 참고.
Node.js 환경에서 순환 참조를 하는 경우 한 모듈이 먼저 로딩되기 때문에, 동기로 로딩하는 경우, 한 쪽에서는 null, 한 쪽에서는 정상 로딩이 될 수 밖에 없다. 아니면 명확한 순서를 지정해준다면 해결할 수도 있겠지만(A[A.B = null]->B[B.A = A]->[A.B = B]), 순서를 명시하는 API가 따로 있는지 잘 모르겠다.
한 쪽에서 느린 초기화를 진행한다. (Lazy-Init) - 순서 정하기와 사실상 동일함.
순환 참조 관계에 있는 두 객체를 제 3의 객체에 의존하도록 한다. 관련 스택 오버 플로우 - 이 부분은 잘 이해하지 못 했다.
모듈의 기능을 객체가 아닌 함수 단위로 노출한다. 진입점이자 주가 되는 함수를 module.exports로 내보내는데, 따라서 const logger = require('./logger')와 같이 바로 사용할 수 있는 함수가 된다. 또한, logger.verbose(msg); 와 같이 서브 함수들도 내보내, 사용하는 입장에서 기능의 중요도를 쉽게 파악할 수 있게 한다.
1 | module.exports = mainFn; |
(ex)
1 | // 메인 함수 |
prototype 기반으로 생성자를 만들거나, ES6 Class를 활용하여 생성자를 만들어, 생성자를 내보낸다. 사용하는 입장에선 객체의 기능을 확장할 수도 있고, 쉽게 인스턴스를 생성할 수도 있고, 사용하기도 깔끔한 방법이다.
1 | module.exports = class Logger { |
생성자 내보내기와 거의 같지만, 싱글톤이 자동으로 구현되는 셈이므로 쉽게 활용하기 좋다.
1 | class Logger { |